


El archivo robots.txt proporciona la información de tu página web a los rastreadores.
Se utiliza para evitar que tu página web se sobrecargue con solicitudes. Con las etiquetas noindex, puedes mantener una página web fuera de Google.
El archivo robots.txt sirve para gestionar el tráfico de rastreadores e indexar tu página web y se tiene que colgar en la raiz principal de tu dominio.
Las instrucciones de los archivos robots.txt sirven de indicaciones para los rastreadores.
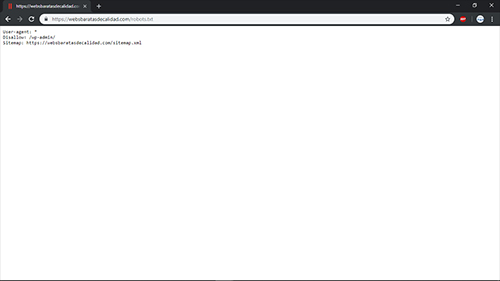
Ejemplo de un archivo robots.txt (Se puede editar con el bloc de notas)
User-agent: *
Disallow: /wp-admin/ (Si utilizas wordpress)
Sitemap: https://nombredetudominio.com/sitemap.xml
Los comandos más utilizados son:
Para Permitir el acceso completo a todos los robots:
User-agent: *
Disallow:
Para bloquear toda la página web:
Disallow: /
Para bloquear un directorio y su contenido:
Disallow: /directorio/
Para bloquear una página web concreta:
Disallow: /pagina-privada.html
Para bloquear todas las imágenes de la página web:
User Agent: Googlebot-Image
Disallow: /
Para bloquear una sóla imagen:
User-agent: Googlebot-Image
Disallow: /imagen/privada.jpeg
Para bloquear un tipo de archivo concreto:
User-agent: Googlebot
Disallow: /*.png$
Para bloquear una secuencia de caracteres:
User-agent:
Disallow: /directorio-privado*/
Para bloquear URLs que terminen en una forma concreta:
User-agent: *
Disallow: /*.pdf$

